ZFS RAIDZ vs. traditional RAID
How does ZFS RAIDZ compare to its corresponding traditional RAID when it comes to data recovery?
You should look elsewhere for information about performance, disk space usage, or maintenance.
I only cover the data recovery side of things.
Conceptual differences
- Traditional RAID is separated from the filesystem.
In traditional systems, one can mix and match RAID levels and filesystems.
- Traditional RAID can be implemented in hardware.
However, no hardware controller is implementing RAIDZ (as of mid-2021).
- RAIDZ is integrated with ZFS. You cannot use it with any other filesystem.
- ZFS uses an additional checksum level to detect silent data corruption when the data block is damaged, but the hard drive does not flag it as bad.
ZFS checksums are not limited to RAIDZ.
ZFS uses checksums with any level of redundancy, including single-drive pools.
Equivalent RAID levels
As far as disk space goes, RAIDZn uses n drives for redundancy. Therefore
- RAIDZ (sometimes explicitly specified as RAIDZ1) is approximately the same as RAID5 (single parity),
- RAIDZ2 is approximately the same as RAID6 (dual parity),
- RAIDZ3 is approximately the same as (hypothetical) RAID7 (triple parity).
Disk space overhead is not precisely the same. RAIDZ is much more complicated than traditional RAID,
and its disk space usage calculation is also complicated.
Various factors affect RAIDZ overhead, including average file size.
On-disk layout
RAIDZ layout is not like any other RAID.
| RAID5 |
| Disk 1 |
Disk 2 |
Disk 3 |
Disk 4 |
| 1 |
2 |
3 |
P |
| 5 |
6 |
P |
4 |
| 9 |
P |
7 |
8 |
| P |
10 |
11 |
12 |
| RAIDZ |
| Disk 1 |
Disk 2 |
Disk 3 |
Disk 4 |
|
P |
1 |
P |
2 |
|
P |
3 |
4 |
X |
|
P |
5 |
6 |
7 |
| 8 |
P |
9 |
10 |
RAID5 places blocks in a regular pattern.
You only need to know the block number (address) to determine which disk stores the block, at what address, and where the corresponding parity block is.
Also, with N disks, exactly one parity block is stored for every N-1 data blocks.
In RAIDZ, ZFS first compresses each recordsize block of data.
Then, it distributes compressed data across the disks, along with a parity block.
So, one needs to consult filesystem metadata for each file to determine where the file records are and where the corresponding parities are.
For example, if data compresses to only one sector, ZFS will store one sector of data along with one parity sector.
Therefore, there is no fixed proportion of parity to the data.
Moreover, ZFS sometimes inserts padding to better align blocks on disks (denoted by X in the above example), which may increase overhead.
Recovery from drive failures
Simplifying, there are two types of drive failures.
- Fail-stop - a disk either fails
in its entirety or specific sectors report errors when read.
- Silent data corruption - the drive returns incorrect data without any warning and without any method to discern that the data is, in fact, incorrect.
The distinction is essential because parity RAID can reconstruct one bad data block for each available parity block,
but only if you know which block is damaged.
With fail-stop failures, ZFS RAIDZn is identical to its corresponding traditional RAID.
When a drive fails completely, you know that all blocks stored on that drive are missing, and you need to reconstruct them.
With silently corrupt data, RAIDZn can reconstruct damaged data, thanks to the extra checksum provided by ZFS.
However, having no extra help, traditional RAID does not recover from silent data corruption because it does not know which block to reconstruct.
Recovery from loss of metadata
Recovery of RAIDZn
is very different from traditional RAID if the RAID metadata, such as block size and disk order, is lost.
Traditional RAID is regular.
Once you know block size, RAID level, and disk order, you can convert any array data block address
to its corresponding disk and address on disk and determine where the corresponding parity block is.
Because the block and parity patterns are regular,
filesystem-agnostic statistical analysis tools (like Klennet RAID Viewer) are very effective with traditional RAID.
In most cases, one can figure out the layout without any knowledge of the filesystem in use.
RAIDZn is not regular.
It does not have a fixed block size, and there is no set pattern of data and parity blocks.
The physical layout depends on what data is written to disks and in what order.
So, there is no way one can determine the layout without including the filesystem in the analysis.
This, while doable, significantly increases computational requirements.
It also prevents analysis by filesystem-agnostic RAID analysis tools.
Write hole
Write hole is a failure mode of the traditional parity RAID.
In traditional RAID5 or RAID6, parity blocks must always match their corresponding data blocks.
However, parity and data blocks are written to different disks.
If power fails mid-write, it is possible that some disks complete their writes and some others don't.
Therefore, some disks contain old (pre-update) data while the other disks contain new (post-update) data.
In this case, parity no longer matches the data.
Even worse, it is not possible to tell which one is correct (without utilizing some external checksum).
This failure mode is called write hole.
One can't fix the write hole in traditional RAID without introducing significant additional complexity and possibly some speed penalty.
Hardware RAID controllers mitigate the write hole problem by using battery backup; software RAID relies on UPS.
Unfortunately, neither of these workarounds is 100% effective.
While battery power protects against power outage, OS or firmware crash is no less damaging.
ZFS works around the write hole by embracing the complexity.
So it is not like RAIDZn does not have a write hole problem per se because it does.
However, once you add transactions, copy-on-write, and checksums on top of RAIDZ, the write hole goes away.
The overall tradeoff is a risk of a write hole silently damaging a limited area of the array (which may be more or less critical) versus the risk of losing the entire system to a catastrophic failure if something goes wrong with a ZFS pool.
Of course, ZFS fans will say that you never lose a ZFS pool to a simple power failure, but empirical evidence to the contrary is abundant.
Rebuild speed
After replacing a bad drive, the RAID regenerates data from the bad drive to the new drive.
This process is typically called rebuild (ZFS sometimes calls it resilvering).
There are two significant metrics:
- Rebuild speed, measured in megabytes per second.
- Rebuild time - the amount of time required to rebuild all the missing data.
and two significant considerations:
- The rebuild speed for traditional RAID is much faster.
However, traditional RAID has to rebuild both used and free blocks.
- The rebuild speed for ZFS RAIDZ is slower.
However, RAIDZ only needs to rebuild blocks that do hold data.
RAIDZ does not rebuild the empty blocks, thus, completing rebuilds faster when a pool has significant free space.
In a traditional RAID, where all blocks are regular, you take block 0 from each of the old drives,
compute the correct data for block 0 on the missing drive, and write the data onto a new drive.
You do this for all blocks, even for the blocks that hold no data
because the traditional RAID controller does not know which blocks on the RAID are in use and which are not.
If the array is otherwise idle, serving no user requests during a rebuild,
the process is done sequentially from start to end,
which is the fastest way to access rotational hard drives.
ZFS uses variable-sized blocks.
Therefore, for each recordsize worth of data, anywhere from 4 KB to 1 MB, ZFS needs to consult the block pointer tree to see how data is laid out on disks.
Because block pointer trees are often fragmented, and files are often fragmented,
there is quite a lot of head movement.
Rotational hard drives perform much slower with a lot of head movement,
so the megabyte-per-second speed of the rebuild is slower than that of a traditional RAID.
Now, ZFS only rebuilds the part of the array in use, and it does not rebuild free space.
Therefore, on lightly used pools, it may complete faster than a traditional RAID.
However, this advantage disappears as the pool fills up.
Summary
ZFS and RAIDZ are better than traditional RAID in almost all respects,
except when it comes to a catastrophic failure when your ZFS pool refuses to mount.
If this happens, recovery of a ZFS pool is more complicated and
requires more time to recover than a traditional RAID.
Again, this is because ZFS and RAIDZ are much more complex.
This reflects the Catch-22 of complexity:
- A more complex system can be made more robust against a larger set of anticipated failures than a simpler system.
- As complexity increases, unanticipated failures become more challenging to recover from than a simpler system.
Bonus - entropy histograms
As a bonus, let's look at entropy histograms used to determine RAID block size in traditional RAID.
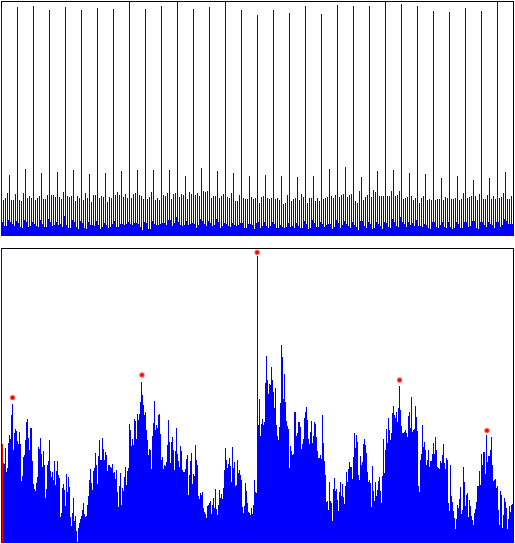
Entropy histograms for RAID5 (top) and RAIDZ (bottom);
The X-axis shows disk addresses (LBAs), Y-axis shows differential entropy
You see, the RAID5 histogram (the top one) is beautifully simple, showing RAID block boundaries with a good signal-to-noise ratio.
Each peak on the top histogram corresponds to a change from one block to another, the distance between peaks indicating block size.
The RAIDZ histogram (the bottom one) is much more challenging to interpret.
Peaks labeled with red dots may look like candidates for block boundaries, but they are not because the peaks are not equidistant.
Again, the bottom line is that RAIDZ analysis is much more complicated than what we do for traditional RAID.
Traditional tools are useless or require much more skill to interpret results correctly.
Filed under: ZFS.
Created Thursday, July 4, 2019
Updated 01 September 2019
Updated 14 June 2021