RAID analysis
Background
Klennet Recovery uses entropy-based analysis to detect RAID layouts.
The analysis process is semi-automatic but requires some understanding of the underlying principles.
Entropy is a measure of randomness in the data.
If you are interested in mathematical details, refer to this Wiki page.
For practical purposes, we first need several basic statements:
- Empty areas on the disk, filled with zeroes, have zero entropy.
- Predictable data (plain text, uncompressed images, or program code) has low entropy.
- Compressed data (ZIP archives, compressed images, and video files) has high entropy.
-
Encrypted data has the maximum possible entropy, making analysis impossible.
Therefore, you cannot use Klennet Recovery to analyze full-disk encrypted arrays.
After that, there are some empirical observations:
- On a parity-based array, like RAID5, parity blocks tend to have higher absolute entropy values than data blocks.
- The change in entropy is highest on the RAID block boundaries, both in RAID5 and RAID0 arrays.
- Similar data has similar entropy values.
Therefore, the change in entropy between adjacent array blocks tends to be the smallest.
Based on these three observations, Klennet Recovery
- shows you charts for you to pick the correct block size,
- detects parity blocks in RAID5, and
- produces the order of data blocks.
This allows the detection of the array configuration.
However, due to the statistical nature of the analysis, it cannot reliably mark the array boundaries.
It works best when the disks or partitions are allocated to only one RAID in their entirety.
Capabilities
As of the current version, Klennet Recovery RAID analysis supports RAID0 (no parity) and RAID5 (single parity) arrays,
including RAID5 with one missing disk.
Arrays encrypted with full-disk encryption are not supported, as the entropy-based analysis does not work on encrypted data.
Basic workflow
Your activities generally move from left to right when translated to toolbar buttons.
- Get a sample of data from disks.
- Look at the entropy graph and figure out the block size. Klennet Recovery computes the corresponding starting offset automatically.
- Configure the number of parities and missing disks.
- Take a look at a block map and verify the block map is consistent.
- Rearrange disks to produce one of the traditional layouts (optional).
- Save the configuration as a virtual array which you can then process as a typical hard drive.
Sampling controls
Sample size
This setting controls the sample size per disk. The following considerations apply:
-
Klennet Recovery samples disks in relatively large blocks, 1 MB to 4 MB.
If all disks provide all-zero data for the entire block, the block is discarded and not counted toward the sample size.
- No more than half of the disk capacity is sampled.
- Larger samples provide more stable results.
- Larger samples use more RAM.
-
Since the output is recalculated every time you switch views or change parameters, smaller samples provide better responsiveness.
With a large sample size, it may feel sluggish even on a high-end PC.
Sampling direction
Front-to-back sampling produces repeatable results.
A random sampling of a large disk produces slightly different results each time.
If you get an unclear picture, taking another random sample may provide a picture that is a little easier to read.
Starting and stopping sampling
Every time you start sampling, any previously collected data is discarded.
If you stop sampling midway, the data collected up to that point is retained and used,
no matter how small the amount.
View modes
Entropy views
Entropy views show entropy change over the address on the disk.
The X-axis is LBA; Y-axis is the change in entropy from one LBA to the next.
The axes are intentionally not labeled.
Absolute values change so much from array to array as to be useless.
The chart highlights starting point of RAID blocks in red, depending on a block size setting.
You should change the block size to align red highlights with the peaks on the chart, as illustrated below.
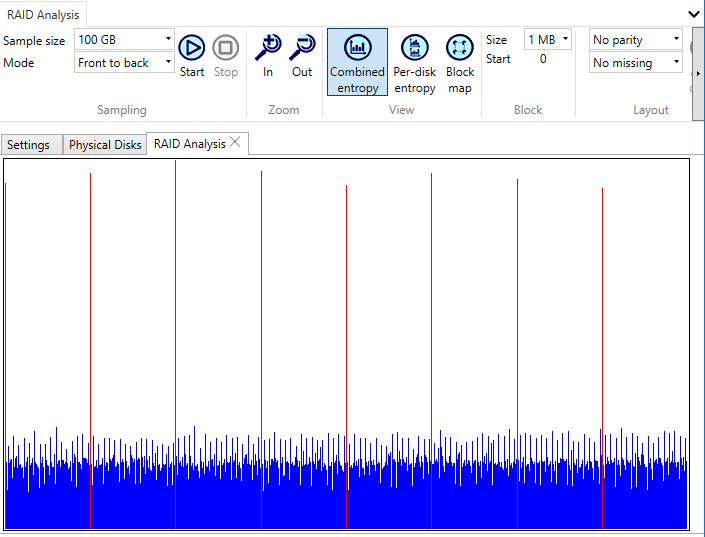
Combined entropy view of a RAID with the block size configured.
Note the red highlight on the highest peaks.
These peaks correspond to a change from one RAID block to the next.
The Combined entropy view shows the average for all disks.
Per-disk entropy shows multiple charts for each disk individually.
The per-disk view is useful to eliminate a stray drive that is not a member of the array, as in the example below.
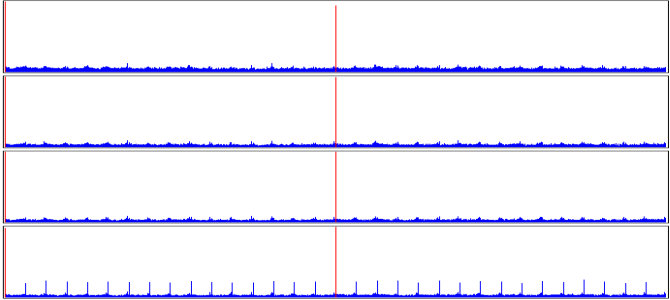
Per-disk entropy view of RAID disks with one extra disk.
The bottom disk is from a different array (albeit using the same block size).
Block map
The Block map view shows the detected position of
the data and parity blocks on the disks.
The data blocks are numbered 1 through the number of data blocks, and parity blocks are shaded.
Arrows indicate the ordering of data blocks, pointing from each block to the next in the sequence.
If you can't make heads or tails of the block map, try the following:
- check the number of parities and missing disk settings,
- try a different block size.
Block parameters
Size
This setting controls the block size for the array.
While in the Combined entropy view,
adjust the block size so that red highlights align
with the set of the highest peaks in the entropy view.
Normally, the correct block size stands out quite distinctly.
However, there is an exception:
if the filesystem cluster size is larger than the block size, you get harmonics in the entropy chart.
Every peak where the filesystem cluster boundary coincides with the RAID block boundary is higher than the peaks where they do not.
If you see a pattern like that, try higher block size first, then go to the lower block size, until the valid block map is produced.
This also applies as a general advice: when trying for block sizes, go in order from higher to lower.
Start
This field displays the starting offset derived from the entropy chart for the specified block size.
It is provided for your reference and is not editable.
RAID data on a disk sometimes does not start at sector 0:
- for a software RAID, there can be a partition table before the array members;
- it's more rare for a hardware RAID, but there may be some controller metadata before the array members.
The offset accounts for whatever there may be before the array members. It is used automatically when the virtual array is created.
Layout parameters
Number of parities
For a RAID0, set to No parity.
For a RAID5, set to One parity.
Normally, you know if you have RAID5 or RAID0 either because you set it up or from the person who did.
If you do not, try both settings and see which one produces the usable block map.
Number of missing disks
For a RAID5, set to One missing if a disk is missing from the set.
Otherwise, use No missing.
Auto order
If the detected block layout is consistent,
this command reorders disks to match one of the canonical representations of the array layout.
Some examples of canonical layouts are:
| RAID0 |
|
RAID 5 asymmetric-left |
|
RAID 5 symmetric-right |
| 1 | 2 | 3 |
|
1 | 2 | 3 | P |
|
P | 1 | 2 | 3 |
| 4 | 5 | 6 |
|
4 | 5 | P | 6 |
|
6 | P | 4 | 5 |
| 7 | 8 | 9 |
|
7 | P | 8 | 9 |
|
8 | 9 | P | 7 |
| 10 | 11 | 12 |
|
P | 10 | 11 | 12 |
|
10 | 11 | 12 | P |
Klennet Recovery builds the block map on the disks as the disks are ordered.
Auto order button reorders the disks:
- RAID0 is reordered left-to-right,
- RAID5 is reordered to either symmetric or asymmetric left-ordered or right-ordered variants,
depending on the input.
The Auto order button is unavailable
if automatic reorder cannot convert the layout to any of the above representations.
Finalizing a RAID
Once satisfied with the layout, click Use virtual RAID to create a virtual RAID device,
which you can then process with the filesystem scanner.
I recommend that you use the Auto order function to reorder the disks before using the RAID
because certain performance optimizations are only available for canonical layouts.