Monitoring disk activity during recovery
Klenet ZFS Recovery has been discontinued.
ZFS recovery features have been integrated into Klennet Recovery proper.
Please see
The original documentation is still available for existing users.
During the disk scan, analysis, and file copy, Klennet ZFS Recovery provides an overview of disk activity.
Keep an eye on it, or at least look at it every now and then.
Disk activity view helps you to:
- see if there are any problems reading the disk, and
- identify the offending disk, within reason (see Tricks and Quirks below).
Disk activity view
Disk activity view is a table showing certain parameters for each disk involved in the recovery.
The data is updated once per second.
- Disk name, rather obviously.
-
Response time.
The time it took the disk to process the request (in milliseconds).
The indicated value is the largest one seen during the last second (since the last update).
-
% Time.
Indicates disk utilization averaged over the last one-second interval.
100% indicates the disk was busy all the time, and 0% indicates the disk was idle.
-
Speed and IOPS.
Average read speed (in bytes per second) and IOPS (number of requests per second).
These are mostly provided for entertainment.
-
Delays.
This is an important metric.
The delay counter is increased every time the disk takes over 750 ms to process a request.
The delay does not always mean there is a bad block, just that it took unusually long to process the request.
A high delay count (100 or more) on a single disk almost always indicates a faulty disk.
There are a few exceptions, though - see Tricks and Quirks below.
When Delays increase, the corresponding drive is highlighted in red.
The highlight then decays over several seconds.
You can see it in the screenshot below (Disk4 is listed in dark red).
The response time was already back to normal when I took the screenshot, and the highlighting was already at half brightness.
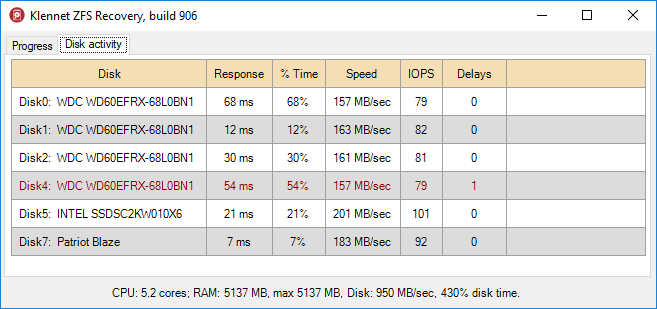
Klennet ZFS Recovery disk activity view.
Tricks and quirks
1.
In some cases, mutual interference exists between the disks attached to the same controller.
When a disk locks up while trying to work around a bad sector, it may cause the entire bus to lock up.
Then, all the disks on the same bus will delay their requests until the faulty disk completes its retry attempts.
ZFS Recovery indicates this in the disk activity view as several disks having a problem simultaneously.
This especially applies to USB-to-SATA converters, which I strongly recommend you avoid like the plague.
If you see this happening, examine SMART data on all the disks and identify the faulty one.
2.
If you use power saving, some or even all of the disks may be asleep and spun down when you start either analysis or copying.
The first read request causes disks to spin up, and this certainly takes longer than a 750-millisecond threshold.
So each spin-up will increase Delays by one.
This is why you should not be worried if you see a Delays value of one or two, especially immediately after you start scanning or copying.
3.
Sum of % Time values for all disks does not always match % Disk Time value displayed in the overall performance overview at the bottom of the window.
This is because the sampling for the two is done at different points in time and frequencies.
Also, if you are reading sparse VHD or VHDX disk images, the values do not match because of how sparse areas are counted.
Identifying a faulty disk
If one of the disks indicates Delays much higher than all others, and all disks are in use, then it is the most likely candidate.
If there are several disks with high Delays value, or if you see multiple disks locking up at the same time, suggesting cross-disk interference, time to do a S.M.A.R.T. check.
Pull the attributes from every disk and examine the raw values.
- On Linux, use smartctl.
- On Windows, I recommend Hard Disk Sentinel for its ability to see through many of the RAID controllers.
Look at the Raw columns for the attributes, not Value columns.
Check the following attributes:
- Reallocated Sectors Count
- Current Pending Sectors Count
- Offline Uncorrectable Sectors Count
Any disk with a non-zero raw value for any of these attributes should be considered faulty and not used.
It is also quite possible for a disk to have good S.M.A.R.T. attributes and still be faulty.
There is no replacing human judgment.
If in doubt, file a support request.
Possible corrective actions
This way or another, you need to eliminate disks that do not work from the process and replace them with something which works.
There are three common options:
- Replace the faulty disk with a disk image file,
- replace it with its clone on another disk, or
- redundancy permitting, exclude the disk from the analysis altogether (I don't recommend it, though).
I recommend using a disk image file (copy of the entire disk content in a file) instead of a clone (copy of the entire damaged disk on a new good disk).
-
If you go with a clone and the target drive is larger than the original drive, ensure the target is zeroed before cloning.
Otherwise, residual data at the end of the clone may contaminate the analysis.
-
If you choose a disk image file, please put each disk image file onto its own physical drive.
Also, do not place multiple disk image files onto a single large RAID array.
The recovery process is highly parallelized, and having two parallel requests compete for a physical drive kills performance.
-
In any case, you will need software to create either a clone or a disk image file.
- On Linux, use ddrescue.
-
On Windows, I recommend using the evaluation version of my Klennet Recovery, but there are plenty more.
For a one-time job, you don't need a license key; just use the demo.
Another option is to evaluate how much redundancy you had before the pool failed,
how much you still have, and if you can tolerate losing one more drive.
For example, if you had 10 drives in a RAIDZ2 setup and you have all the drives,
and determined that only one is faulty, you may exclude the offending drive from the
analysis, probably with no ill effects.
However, it is difficult to be perfectly sure there will be no ill effects.
What if there were some resilver/rebuild attempts? Is one of the drives slightly out of sync?
The complexity of ZFS makes the decision difficult, so I would not recommend it.
Better stick to disk image files.