ZFS basics
Klenet ZFS Recovery has been discontinued.
ZFS recovery features have been integrated into Klennet Recovery proper.
Please see
The original documentation is still available for existing users.
ZFS is a hybrid of filesystem and RAID.
This is an advantage when the filesystem works, because the knowledge of the underlying physical layout allows for some cool optimizations.
However, when the filesystem breaks down, it complicates matters.
In an orthodox case when filesystem and RAID are separated, the recovery can be done in two steps, first RAID and then filesystem.
With ZFS, RAID and filesystem must both be recovered at once as they are unseparable.
As far as recovery goes, there are three interesting features: pool layout, RAIDZ, and data compression.
ZFS pools, VDEVs, and physical drives
In brief, ZFS handles physical drives as follows
-
Physical drives are combined to form VDEVs (Virtual Devices).
This is where most of the magic happens.
VDEVs can be
- Simple, consisting of a single physical drive.
- Mirror, or n-way mirror, storing identical copies of data on two or more drives, same as traditional RAID1.
- RAIDZ, which is a funny variation of RAID5 (discussed later in more detail).
- RAIDZ2 or RAIDZ3, where RAIDZ2 is a funny variation of RAID6, and RAIDZ3 is the same but triple-redundant.
-
VDEVs are then combined to form a ZFS pool.
The data in the pool is distributed across all the VDEVs, in effect providing additional level of striping.
The pool may combine VDEVs of different RAID levels;
furthermore, pool expansions may eventually lead to weird configurations which are difficult to describe
and failure modes which are difficult to understand.
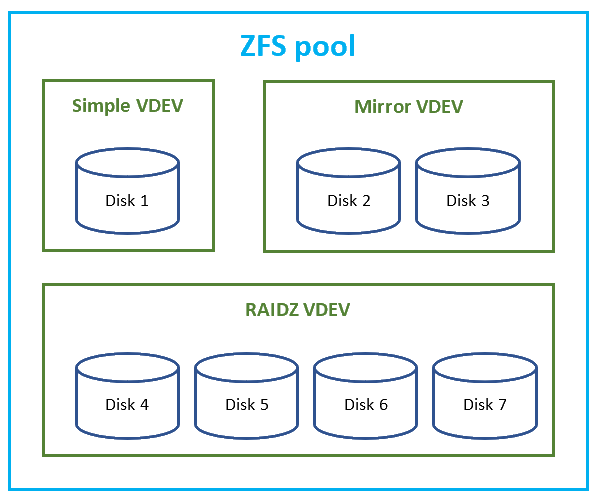
Relationship between ZFS pools, VDEVs, and physical disks
Fortunately, VDEVs can't be nested inside VDEV's, so that limits the complexity somewhat.
The map of what physical drive maps to which VDEV and how VDEVs are combined is stored in disk labels.
Two disk labels are stored at the front of each physical drive, and two more are stored at end.
Having several copies in fixed locations provides good protection against accidental formatting with another filesystem
and also against accidental overwrite with a disk image.
However, if the drive is reused for another ZFS pool, the labels will be overwritten because they are stored in a fixed
location. New filesystem will write its own labels into the same fixed location, overwriting old ones.
RAIDZ
RAID-Z is a variation of RAID5 with no regular parity and data block layout.
There are some advantages in RAIDZ, mostly its ability to avoid the "write hole" problem of the traditional parity RAID.
The significant disadvantage is that overhead depends both on number of disks and on I/O size (how many bytes are written in a single operation).
In RAID5, no matter how many disks are in the array, the overhead is always the size of one disk.
In RAIDZ, overhead may be same size as data (for small writes) no matter how many disks are used.
The layout, however, is fancy. The width of the stripe depends on how many blocks are involved in a single write operation.
| Disk 1 | Disk 2 | Disk 3 | Disk 4 |
|---|
| P1 |
D1 |
P2 |
D2 |
| D2 |
P3 |
D3 |
D3 |
| P4 |
D4 |
D4 |
D4 |
You can see that if you need to write just one block of data (D1), the parity occupies the same size as the data block.
As the transaction size increases, overhead decreases, eventually becoming the same as in traditional RAID5.
Furthermore, there are some weird restrictions on the layout.
One of them is that small transactions may be padded to improve allocation efficiency.
All of this caused people to suggest (or even insist on) some rules about how the number of drives must be multiple of something
for a given RAIDZ level. There is no much efficiency in that, however.
Data compression
Many filesystems feature built-in data compression (NTFS had it since time immemorial), but ZFS takes it one step further.
ZFS compresses both user data (file content) and its own metadata (filesystem internal tables).
In recovery, this slows scans somewhat because looking for compressed data is slow, but the slowdown is not really that bad.
Filesystem metadata
ZFS uses dnodes, similar to EXT inodes,
and trees of block pointers, also similar to EXT, to store locations of files.
However, unlike EXT, dnodes are not stored in fixed locations on the volume.
Instead, ZFS uses object sets, files holding arrays of dnodes, something similar to NTFS MFT.
Copy-on-write
To maintain data integrity in case of a power failure or a full-stop system crash, ZFS uses copy-on-write.
When the data is to be modified, the new version of data is written into an empty location on the volume,
and then the pointers are updated.
Because of this, older versions of data, both file data and metadata, can be found all over the volume.
From the data recovery point of view, this improves chances to find older versions of the files, for both deleted and modified files.
However, full scan of all the disks in the pool is required to find these older versions, because they are no longer referenced from the root of the filesystem metadata.
Checksums
ZFS calculates and stores checksums for both file content and metadata.
Many different checksum algorithms of various reliability and CPU requirements are supported.
Checksumming allows to choose a valid copy of the metadata, as multiple copies are commonly stored,
and also allows to detect if part of the data was overwritten and sometimes reconstruct the missing data based on redundancy.
Summary
All in all, ZFS is a complex and complicated filesystem.
Would I use it myself? Probably not. I'd stick with something more orthodox.
However, as far as data recovery goes, ZFS recoverability is good thanks to checksumming and CoW.